
[C++] OpenMP.
OpenMP란?
OpenMP는 공유 메모리 다중 처리 프로그래밍 API로, C, C++, Fortran 등의 언어를 지원하며 여러 플랫폼에서 사용됩니다. OpenMP는 병렬 프로그래밍을 쉽게 하기 위해 설계되었으며, 특정 코드 부분을 병렬로 실행하도록 지시하는 전처리기 지시어(pragma)와 런타임 함수를 제공합니다.
OpenMP의 주요 특징
간단한 병렬 프로그래밍
OpenMP를 사용하면 기존 코드에 변경 사항을 최소화하면서도 병렬 처리 기능을 추가할 수 있습니다.
다양한 플랫폼 지원
Windows, Linux, macOS 등 다양한 플랫폼에서 OpenMP를 사용할 수 있습니다.
C, C++, Fortran 지원
OpenMP는 C, C++, Fortran 등의 언어를 지원하여 다양한 프로그래밍 언어에서 병렬 프로그래밍을 할 수 있습니다.
자동 병렬화
일부 컴파일러는 OpenMP 지시어를 사용하여 자동으로 코드를 병렬 처리할 수 있습니다.
스레드 관리
OpenMP는 스레드 생성, 관리, 동기화 등을 간편하게 할 수 있도록 런타임 함수를 제공합니다.
OpenMP의 장점
병렬 처리 성능 향상
OpenMP를 사용하면 멀티코어 프로세서의 성능을 최대한 활용하여 프로그램의 속도를 향상시킬 수 있습니다.
개발 시간 단축
OpenMP는 기존 코드를 수정하지 않고도 병렬 처리 기능을 추가할 수 있어 개발 시간을 단축할 수 있습니다.
병렬 프로그래밍 경험이 없어도 사용 가능
OpenMP는 비교적 쉬운 인터페이스를 제공하여 병렬 프로그래밍 경험이 적은 개발자도 쉽게 사용할 수 있습니다.
OpenMP의 단점
컴파일러 의존성
OpenMP 프로그램의 성능은 컴파일러의 성능에 크게 의존합니다.
성능 최적화 어려움
OpenMP를 사용하여 성능을 최적화하는 것은 어렵고, 튜닝이 필요한 경우도 있습니다.
병렬 처리 알고리즘 선택
적절한 병렬 처리 알고리즘을 선택하지 않으면 OpenMP를 사용하여 오히려 성능이 저하될 수 있습니다.
OpenMP 사용 예
#include <iostream>
#include <omp.h>
int main() {
int i;
int sum = 0;
#pragma omp parallel for
for (i = 0; i < 100; i++) {
sum += i;
}
std::cout << "sum : " << sum << std::endl;
return 0;
}
위 예제에서 #pragma omp parallel for 지시어를 사용하면 for 루프가 병렬로 실행되도록 지정됩니다. 각 스레드는 자신만의 반복을 처리하고, 최종적으로 결과를 합산합니다.
자.. 여기까지는 구글에다가 OpenMP 가 뭐냐고 검색해보니까 Ai가 설명해준 내용이고…
며칠 전 Omron 변위센서로부터 LB Command를 사용하여 Buffer에 누적된 Data를 수신하는 SOCKET 통신 기능을 구현할 일이 있었다.
수신까지는 문제없었는데 수신한 Data가 아주 많았다.
Data의 양이 많아서 전처리 하는 반복문에서 시간이 꽤나 소요됐었는데, 이수석님이 OpenMP 라는 기능을 알려주셨다.
병렬처리를 할 수 있는 기능이라며 사용해보라고 권유해주셨고 나는 일단 뭣도모르고 아 그렇구나 병렬처리 하는거구나 CUDA 비슷한거겠구나 하고 코드에 때려박았다.
그리고 며칠이 지난 지금 이게 어떤 기능인지 공부하기 위해 이렇게 포스트를 작성하며 무엇인지 검색하고 알아보고 있다.
OpenMP는 기본적으로 위에 구글 Ai 가 소개해준 것처럼 #pragma omp parallel for 를 사용하면 병렬처리를 할 수 있는것이 맞다.
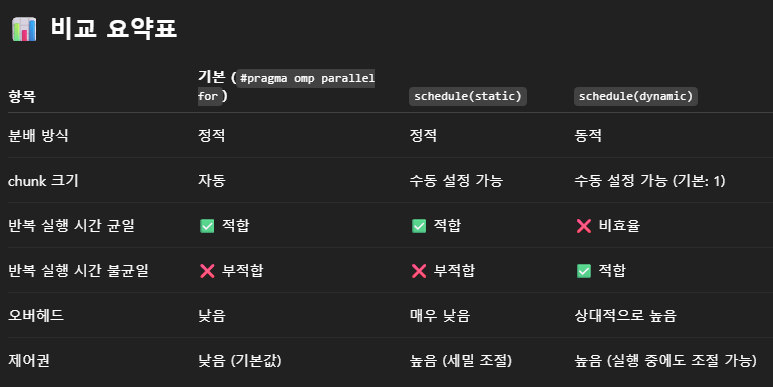
그런데 단순히 여기서 끝이 아니라 schedule 을 활용해 static 또는 dynamic 모드를 설정할 수 있는데.. 이렇게 3가지를 간단히 설명하자면
#pragma omp parallel for
가장 기본적인 OpenMP 동작.
OpenMP는 기본적으로 static 전략을 사용하며 chunk의 크기는 자동으로 할당된다.
#pragma omp parallel for schedule(static)
명시적으로 static 동작을 구현하며 chunk의 크기를 수동으로 조정할 수 있다.
#pragma omp parallel for schedule(dynamic)
동적 스케줄링으로 작동하며 스레드가 작업을 완료하면 새 chunk를 런타임에 요청해서 처리한다.
각 반복의 실행 시간이 불균일할 때 최적의 방법이다.
예시 코드 비교
// 기본 정적 스케줄링
#pragma omp parallel for
for (int i = 0; i < 100; ++i)
work(i);
// 명시적 정적 스케줄링
#pragma omp parallel for schedule(static, 10)
for (int i = 0; i < 100; ++i)
work(i);
// 동적 스케줄링 (작업 부하 불균일시 효과적)
#pragma omp parallel for schedule(dynamic, 5)
for (int i = 0; i < 100; ++i)
work(i);
결론
작업이 균일하다면 schedule(static)이 가장 빠르고 효율적이다.
작업 시간 편차가 많다면 schedule(dynamic)이 좋은 선택이다.
chunk size는 실험적으로 조절하면서 성능 튜닝할 수 있다.
끝.
댓글남기기