
[Python OpenCV] OpenCV-python을 활용한 객체추적 프로그램.
서론
OpenCV란
1) 오픈 소스 컴퓨터 비전 라이브러리 중 하나로 크로스 플랫폼이고 실시간 이미지 프로 세싱에 중점을 둔 라이브러리이다. 여러가지 컴퓨터 언어를 지원하고, 영상 관련 라이브러리로서 표준적 지위를 가지는 프로그램이다.
2) 기능이 다른 프로그램에 비해 매우 방대하고 구현되어 있는 알고리즘 또한 많아서 영상을 기반으로 한 프로그래밍 할 때 기본적으로 사용되는 프로그램이다.
3) 또한 BSD 라이선스를 이용해서 상업적 이용도 가능하기에 이번 프로젝트에 가장 용이하다고 생각해서 사용하게 되었다.
연구 배경 및 필요성
1) 정확한 수치는 항상 환영 받는다. 특히 관공서나 국가 기관에서는 이러한 데이터를 바탕으로 예산을 책정하거나, 지원을 결정하는데 큰 도움을 주기 때문에 이러한 생각을 갖게 되었다.
2) CCTV 영상을 받아서 프로그램을 구현 시킨다면 해당 지역의 시간대와 인구밀도를 측정하는 프로그램으로 활용할 수 있을 것이고, 이러한 결과는 활용 방도에 따라 무궁무진하게 응용될 수 있을 것이다.
3) 여름철 삼척 지역의 해수욕장의 유동인구를 파악할 수 있을 것이고, 이러한 점은 삼척이나 기타 지역에서 해수욕장이나 여러 관광지의 관광객 인원 파악에도 기여할 수 있을 것이다. 이러한 프로그램이 개발된다면 수요에 맞게 여러 곳에서 활용이 가능한 프로그램을 개발하는 것이 이번 프로젝트의 필요성이라고 생각했다.
4) 다수의 CCTV를 동시에 또는 별도로 확인하는 기존의 물리적인 통합관제 시스템은 피해자의 생사가 문제되는 사건의 초기 용의자 추적에 걸리는 시간이 관제인원의 수, 경험 및 신체 상태에 의존적임 복수의 CCTV에서 촬영된 이미지에서 동일한 용의자의 동일성을 인식할 수 있도록 딥러닝 기반의 거리, 위치 및 시야각이 다른 후보 영상을 실시간으로 생성할 수 있는 기술 필요 관제인력의 의존도를 낮추기 위한 초기 용의자의 이동 경로 자동추적 기술 도입 필요하다.
연구의 주제
1) 이미지 및 동영상 Processing에 대해 학습하고 OpenCV 프로그램을 통해 컴퓨터 내에서 영상 처리를 사용해 해당 영상의 움직이는 사물이나 사람에 대해 인식하는 프로그램 개발을 목적으로 한다.
2) 한 물체가 해당하는 영상에 언제부터 등장하고 어느 시간까지 존재하는지, 해당 시간대 동안 얼마나 많은 움직임이 있었는지 파악을 해서 위에 말한 필요성에 부각하게 한다. 더 세부적인 목표는 영상을 통해 해당 영상에 얼마만큼의 실제 유동물체가 있는지 파악하고, 그것이 사람인지 사물인지 파악하고, 해당 움직임이 사람이라면 얼굴 인식 및 해당 영상 내의 움직임을 수치화 하는 것을 목표로 한다.
연구의 방법
1) OpenCV 프로그램 내에 존재하는 알고리즘인 Haar Cascade라는 머신 러닝 기반의 오브젝트 검출 알고리즘을 활용할 것이다. 해당 알고리즘을 선택한 이유는 우리가 개발하고자 하는 프로그램과의 연관성이 가장 깊고, 직사각형 영역으로 구성되는 특징을 사용기 때문에 픽셀을 직접 사용할 때 보다 동작속도가 빠르다는 장점을 가지고 있다.
2) 또한 찾으려는 오브젝트 (해당 프로젝트에서는 얼굴이나 사람)가 포함된 이미지와 오브젝트가 없는 이미지를 사용하여 Haar Cascade Classifier(하르 특징 분류기)에 학습을 시킬 수 있기에 해당 알고리즘을 선택했다. 물론 추가적인 알고리즘 또한 다양하지만 가장 기본적인 알고리즘은 위와 같다.
3) 알고리즘의 단계는 하르 특징 선택(Harr Feature Selection), 적분 이미지(Integral Images), 특징 계산(Adaboost Training)으로 이루어지는 데 자세한 내용은 아래에 더욱 자세하게 설명하겠다.
연구의 구성
1) 연구 방법, 연구 결과,결론 및 한계점,참고 문헌으로 구성했다.
2) 각 부분에 대해서는 우선 연구 방법에서는 코드 설명 및 테스트 결과 출력 및 해당 내용 출력 부분에 대해 설명할 것이고 어떠한 방식으로 영상의 처리가 이루어지고 데이터를 내보내는지 설명할 것이다. 연구 결과에서는 객체 인식을 통한 대략적인 인원 파악 및 데이터 내보내기와 예시를 설명할 것이고, 결론 및 한계점에서는 이번 프로젝트를 통해 구현한 프로그램에 대한 결론과 한계점, 그리고 추후에 보완이 된다면 어떤 점이 가능하고, 발전 가능성에 대해 이야기해볼 것이다.
이론적 배경
OpenCV-python
1) OpenCV-Python은 OpenCV의 파이썬 API들의 집합체이다. 다시 말하면
OpenCV-Python은 OpenCV의 C++ API를 파이썬 언어로 랩핑한 것이다.
2) Python은 스크립트 언어이기 때문에 C/C++와 같은 컴파일 언어에 비해 속도가 떨어진다. 그러나 Python의 이러한 단점은 성능적인 이슈가 있는 부분을 C/C++로 구현한 후 이를 Python으로 불러 사용할 수 있도록 Python과 연동이 가능하다. 다시 설명하면 C/C++로 구현한 코드를 C확장모듈 또는 C확장형 이라고 하고, Python 래퍼로 감싼 후 Python 모듈로 사용하는 것이다. 그러면 Python 언어로 C/C++로 구현한 코드
를 사용할 수 있다.
3) OpenCV-Python은 Numpy라고 하는 수학 연산을 위해 최적화된 라이브러리를 활용하여, 이와 호환되기도 한다. Numpy를 통해 컴퓨터 그래픽스, 이미지 프로세싱, 비전 처리 등에 필요한 행렬연산을 손쉽게 할 수 있도록 한다.
4) 모든 OpenCV 배열 구조는 Numpy 배열로 변환되고 이를 통해 내부 처리를 수행한다. 따라서 Numpy로 할 수 있는 모든 연산은 OpenCV와 호환되어 상호 결합이 가능하다.
5) OpenCV-Python은 컴퓨터 비전에 관련한 다양한 문제를 해결하기 위한 프로토타입을 매우 빠르게 구현할 수 있는 도구이다. 또한 OpenCV의 라이브러리에는 기초 영상 처리부터 고급 수준의 영상처리까지 약 2,500개가 넘는 알고리즘들이 함수로 구성되어 있다.
6) 해당 구성은 다음과 같다.
- 영상 처리, 컴퓨터 비전, 기계 합습과 관련된 전통적인 알고리즘
- 얼굴 검출과 인식, 객체 인식, 객체 3D 모델 추출, 스테레오 카메라에서 3D 좌표 생성
- 고해상도 영상 생성을 위한 이미지 스티칭, 영상 검색, 적목 현상 제거, 안구 운동추적
OpenCV 객체 인식 알고리즘 종류
컴퓨터 비전의 다양한 분야에서 기존의 물체 추적 알고리즘은 주로 온라인 방식을 사용한다. 온라인 방식은 매 프레임마다 물체의 위치 파악과 추적을 위해 큰 계산량을 필요로 한다. 기존의 방식에는 다양한 알고리즘이 있다. 이 6가지 알고리즘의 성능 분석 표를 보겠다.
![]()
현재 6가지의 Tracker 알고리즘에 대한 종류와 성능을 확인했다. 우리 팀에서는 이 알고리즘들의 성능을 비교하고 회의한 결과 CSRT 알고리즘이 객체를 인식하는 속도와 정확도가 뛰어나다고 판단하였고, 현재 우리 삼척 마을 방범대 팀이 추구하는 객체 인식 CCTV의 성능을 보다 높여줄 알고리즘이라 생각되어 CSRT 알고리즘을 선택했다.
연구 방법
Flowchart 설명
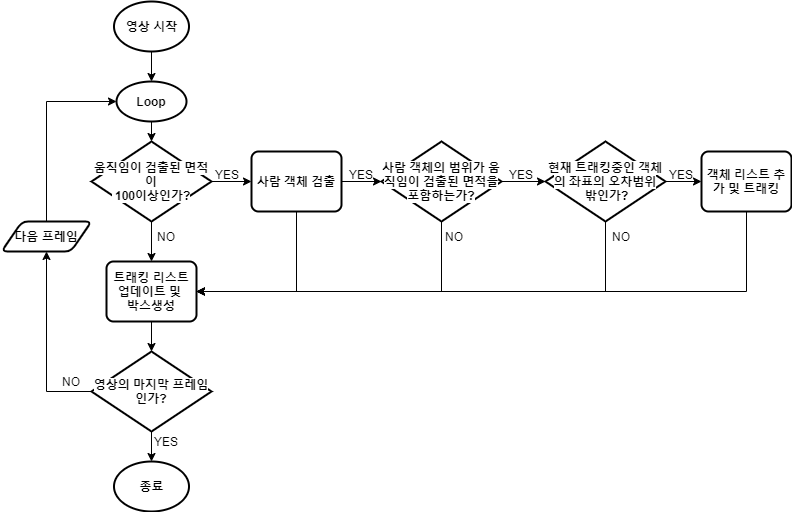
1) 코드를 간략하게 설명하기 위한 흐름도이다. 영상이 시작하면 일단 움직임이 있는 범위면적이 100이상인 좌표를 검출한다. 그 다음 바로 사람객체 검출을 시작하여 프레임에 사람객체를 모두 탐지하고, 움짐임 좌표를 포함하면 객체 리스트에 넣고 객체 리스트에 있는 좌표를 트래킹을 시킨다. 하지만 만약 트래킹할 좌표가 전에 이미 트래킹 중이던 객체이면 하나의 객체를 중복 트래킹하기 때문에 새로운 사람 객체를 트래킹하기 전에 기존에 있던 객체의 오차범위 밖에 있는지 확인하고 트래킹을 시도한다.
2) 코드를 보면 수많은 if문을 건 것으로 보이는데, 이런 많은 조건을 건 이유는 OpenCV에서 기본적으로 제공하는 객체 검출은 성능(속도 저하, 객체 인식 수준 낮음)이 좋지 못하다. 그래서 객체 검출에 정밀도를 높이기 위해 움직임과, 기존 객체의 좌표의 오차범위를 설정하여 조건으로 걸어서 모든 조건을 만족하여야 새로운 사람 객체로 인식하고 트래킹 할 수 있고, 하나라도 조건을 만족하지 못한다면 바로 다음 프레임으로 넘어가기에 불필요한 연산을 조금이라도 줄이기 위해 많은 조건을 걸었다.
사용된 기능요소
Haar Casecade
Haar Casecade는 머신 러닝기반의 오브젝트 검출 알고리즘이다. 이 검출기의 작동은 4단계로, Haar Feature Selection(하르 특징 선택) Integral Images(적분 이미지) Adaboost Training Cascading Classifiers 단계를 거친다. 하르 특징(Haar Feature Selection)은 이미지를 스캔하면서 위치를 이동시키는 인접한 직사각형들의 영역내에 있는 픽셀의 합의 차이를 이용하는 것이다. 하지만 이러한 하르 특징 계산은 매우 많은 소요시간이 걸리며 때문에 이미지를 적분(Integral Images)하는 작업이 필요하다. Adaboost는 하르 특징 선택과정에서 수 많은 특징이 검출되는데 객체 검출을 하는데 도움이 되는 의미 있는 특징을 골라내야 한다. 예를 들어 얼굴을 검출할 때의 예시를 들면,

위의 이미지와 같이 가로 방향으로 검은색 사각영역과 흰색 사각영역이 있는 특징의 경우에는 코와 빰 보다 눈 부분이 더 어둡다는 특성을 사용하고, 세로 방향으로 흰색 사각영역이 있고 좌우에 검은색 사각 영역이 있는 특징의 경우에는 중앙에 있는 코보다 양쪽에 있는 눈 부분이 더 어둡다는 특성을 이용하는 것이다.
Cascading Classiifiers는 이미지에 우리가 원하는 객체보다 그저 빈 공간이나 필요없는 공간이 더 많다. 그래서 필요한 작업으로, 현재 윈도우가 있는 영역이 얼굴 영역인지를 단계별로 체크하는 방법을 사용한다. 낮은 단계에서는 짧은 시간에 얼굴 영역인지 판단하게 되며 상위 단계로 갈수록 좀 더 시간이 오래 걸리는 연산을 수행한다.
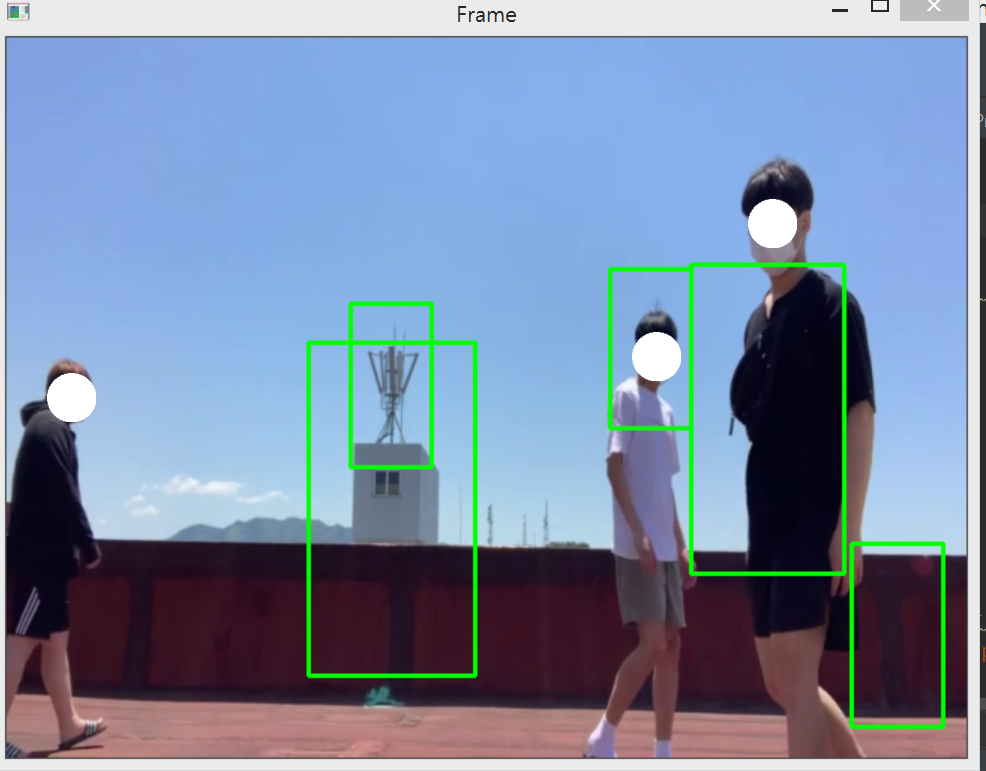
위의 이미지는 오로지 Haar Casecade만을 사용하여 영상의 객체를 잡는 영상을 캡쳐한 사진이다. 보시다시피 무분별한 객체 인식이 이루어진다. 이러한 이유는 그저 opencv에서 기본적으로 제공하는 body객체 탐지(‘haarcascade_fullbody.xml’)를 사용하여 성능이 떨어진다. 만약 시간의 여유가 있었다면, 머신러닝을 우리가 학습을 시켜 좀 더 정확한 객체 인식이 이루어졌을 거다. 그리고 또 하나의 원인으로는, 위에 말한 Adaboost의 기능이 body객체를 탐지하는 분야에서는 성능이 떨어지기 때문이라고 생각한다. 얼굴 같은 경우는, 얼굴 하나에 많은 특징들이 있지만 몸 같은 경우에는 얼굴에 비해 특징이 별로 없고, 어떠한 옷 색깔을 입느냐에 따라 픽셀의 밝기 때문에 객체의 탐지 성능이 떨어진다고 본다.
정적 배경 차분 (Background Subtraction)
배경 차분(Background Subtraction)은 등록된 배경 모델과 현재 입력 프레임과의 차이를 이용하여 객체를 검출하는 방법이다.
배경 영상을 model이라는 용어를 써서 배경 영상을 등록시켜두고 배경 영상과 다른 부분을 찾아서 그 부분이 새로 나타난 객체라고 판단하는 방식으로 작동한다.

위 사진은 배경 차분(Background Subtraction)만을 사용하여 적용한 모습이다. 오른쪽 모습과 같이 배경을 빼고 배경이 있는 프레임과의 차이(변화)가 있는 부분을 하얀색으로 표현한다. 왼쪽 이미지는 오른쪽 이미지의 움직임이 있는 부분의 정보( x, y, w, h, area)를 가져와서 박스와 원을 만들어준 모습이다.
OpenCV 트래커 (Tracker)
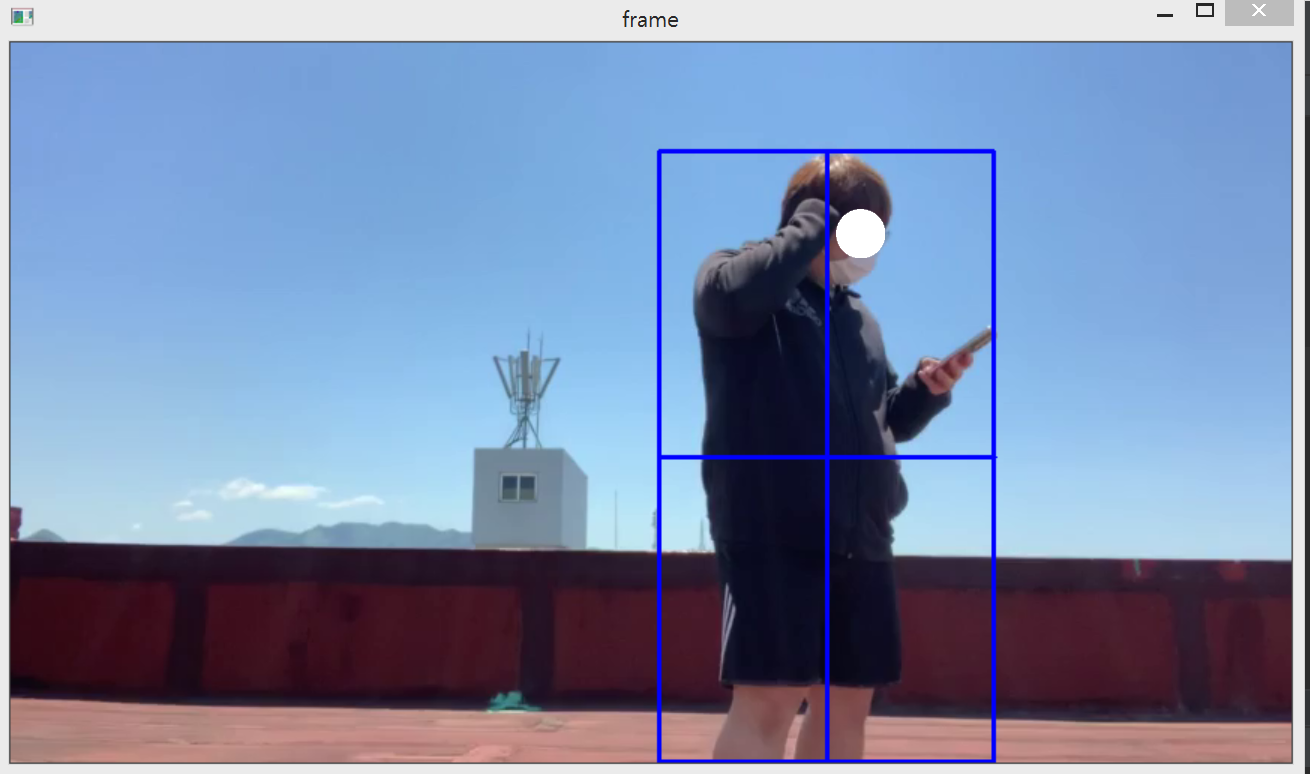

OpenCV에서 제공하는 기능중 하나인 Tracker이다. 이 기능은 사용자가 드래그, 혹은 좌표를 지정하면은 해당 부분의 객체의 움직임에 따라 같이 움직여주는 트래킹을 한다.
트래커의 종류에도 많은 종류가 있으며, Boosting, CSRT, GOTURN, KCF, MedianFlow, MIL, MOSSE, TLD, 등이 있다. 우리는 그 중에서 연산은 느리지만 강력한 트래킹을 보여주는 CSRT를 사용하였으며, 이러한 트래커를 여러게 설정하고 담을 수 있는 MultiTracker를 이용하여 여러 객체들을 추적할 수 있게 하였다.
주요 코드 및 설명
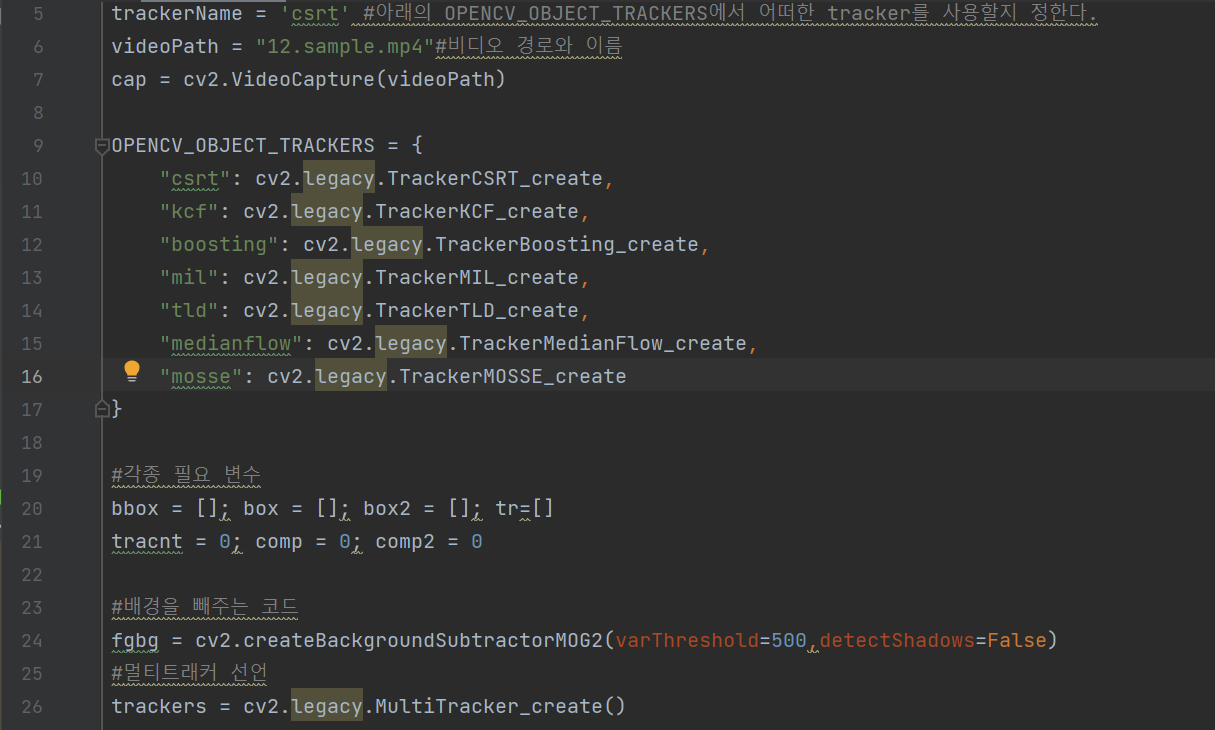
9행의 OPENCV_OBJECT_TRACKERS dictionary는 위의 trackerName에 원하는 트래커 방식을 정하여 이용자가 임의로 정할 수 있게 해준다. 그 아래 videoPath에 영상파일을 넣어주고, cv2.VideoCapture()안에 videoPath를 넣어 영상을 실행 시킬 수 있다. 24행은 배경 제거하는 코드로써, 배경 제거는 객체를 포함하는 영상에서 객체가 없는 배경 영상을 빼는 방법을 말한다. 즉, 배경을 모두 제거해 객체만 남기는 방법이다. 그 옆의 varThreshold 파라미터는 분산 임계값으로써 이 변수의 크기를 높이면 움직임이 커야 객체로 인식한다. 그 아래 26행은 tracker를 담을 수 있는 MultiTracker생성이다.
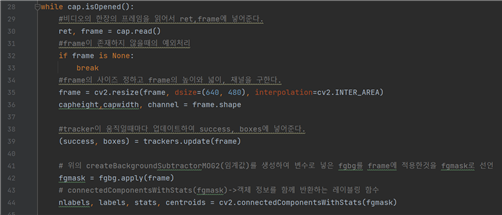
위 코드에서 중요 코드는 39행의 trackers.update(frame)로 multitracker에 담겨있는 트래커가 계속 업데이트되어 객체를 따라 움직이게 해주는 것입니다. 42행의 코드는 위에 배경을 빼주는 코드에 비디오의 한 프레임을 적용하여 변수로 선언. 그 아래 connectedComponentWithStats에 위에 선언한 변수를 파라미터로 적용시켜 레이블링한다.
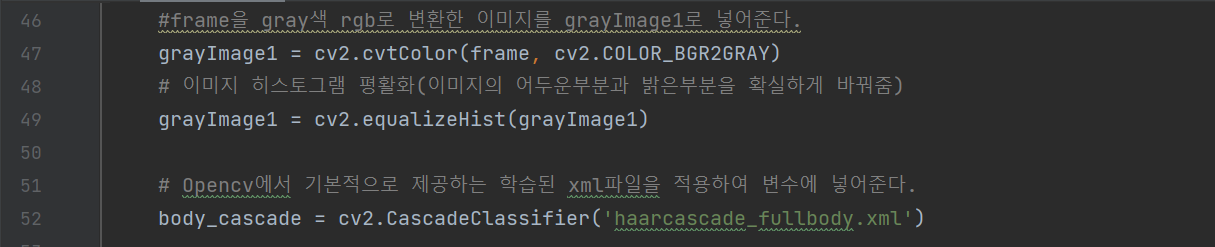 grayImage1 변수는 영상의 한 프레임을 RGB값을 gray색으로 변환시키고 이미지 평활화 하여 밝기가 뚜렷하게 만들어준다. 이 작업은 Cascade기법이 더욱 성능이 좋아지도록 해주는 작업이다. 아래 52행은 OpenCV에서 기본적으로 제공하는 이미 학습된 데이터를 Casecade에 적용시켜 body_cascade변수 선언을 한다.
grayImage1 변수는 영상의 한 프레임을 RGB값을 gray색으로 변환시키고 이미지 평활화 하여 밝기가 뚜렷하게 만들어준다. 이 작업은 Cascade기법이 더욱 성능이 좋아지도록 해주는 작업이다. 아래 52행은 OpenCV에서 기본적으로 제공하는 이미 학습된 데이터를 Casecade에 적용시켜 body_cascade변수 선언을 한다.
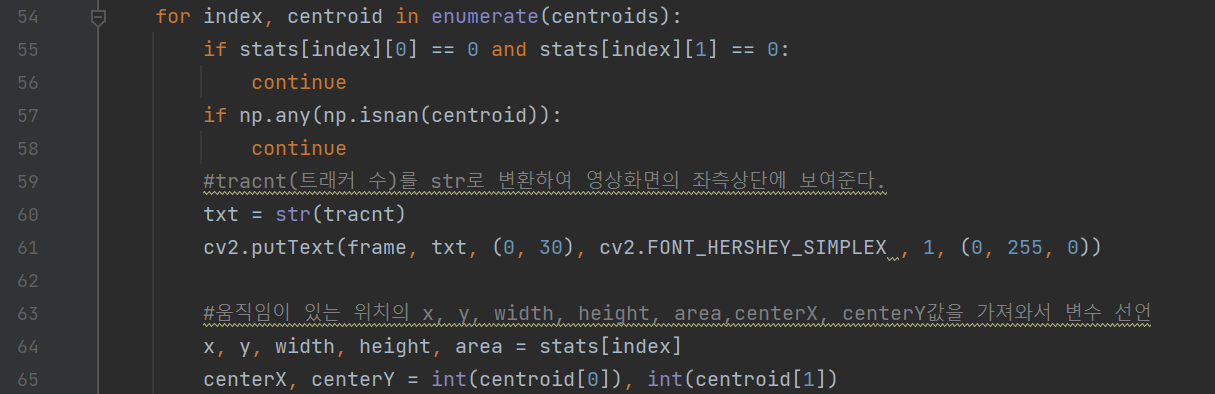 이 코드는 위에서 레이블링한 요소들(stat,centroids)을 가져와서 정보(x,y,width,height,area)를 추출하는 것이다.
이 코드는 위에서 레이블링한 요소들(stat,centroids)을 가져와서 정보(x,y,width,height,area)를 추출하는 것이다.
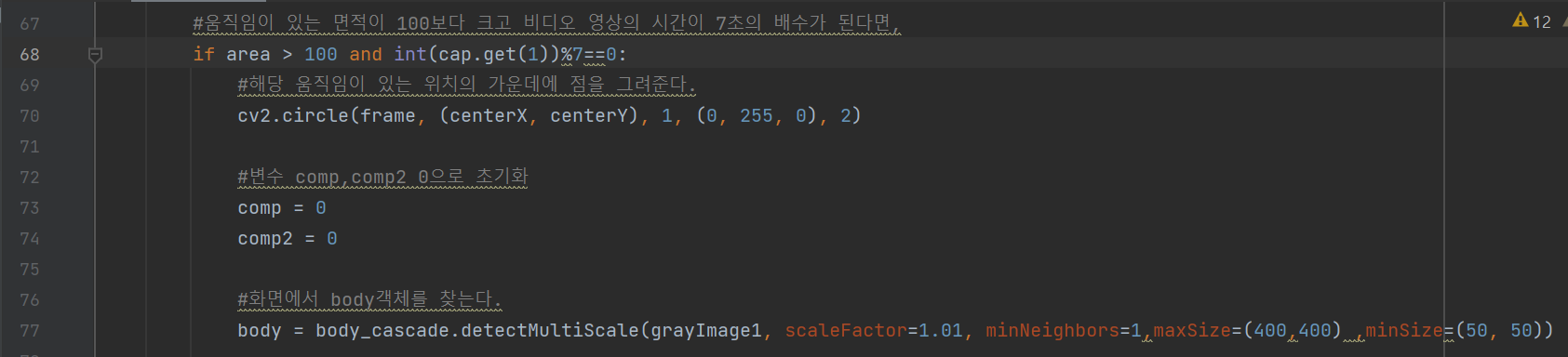 위 레이블링하여 빼내온 정보 중 area(움직임의 면적)의 크기가 100이상 그리고 비디오 시간이 7의 배수의 시간일 때, centerX, centerY 좌표에 조그만한 점을 그려준다. 그리고 77행은 객체를 찾는 코드로써, 움직임의 면적이 100이상이고, 비디오 시간이 7의 배수의 시간일 때 객체를 찾게 하는 것이다.
위 레이블링하여 빼내온 정보 중 area(움직임의 면적)의 크기가 100이상 그리고 비디오 시간이 7의 배수의 시간일 때, centerX, centerY 좌표에 조그만한 점을 그려준다. 그리고 77행은 객체를 찾는 코드로써, 움직임의 면적이 100이상이고, 비디오 시간이 7의 배수의 시간일 때 객체를 찾게 하는 것이다.
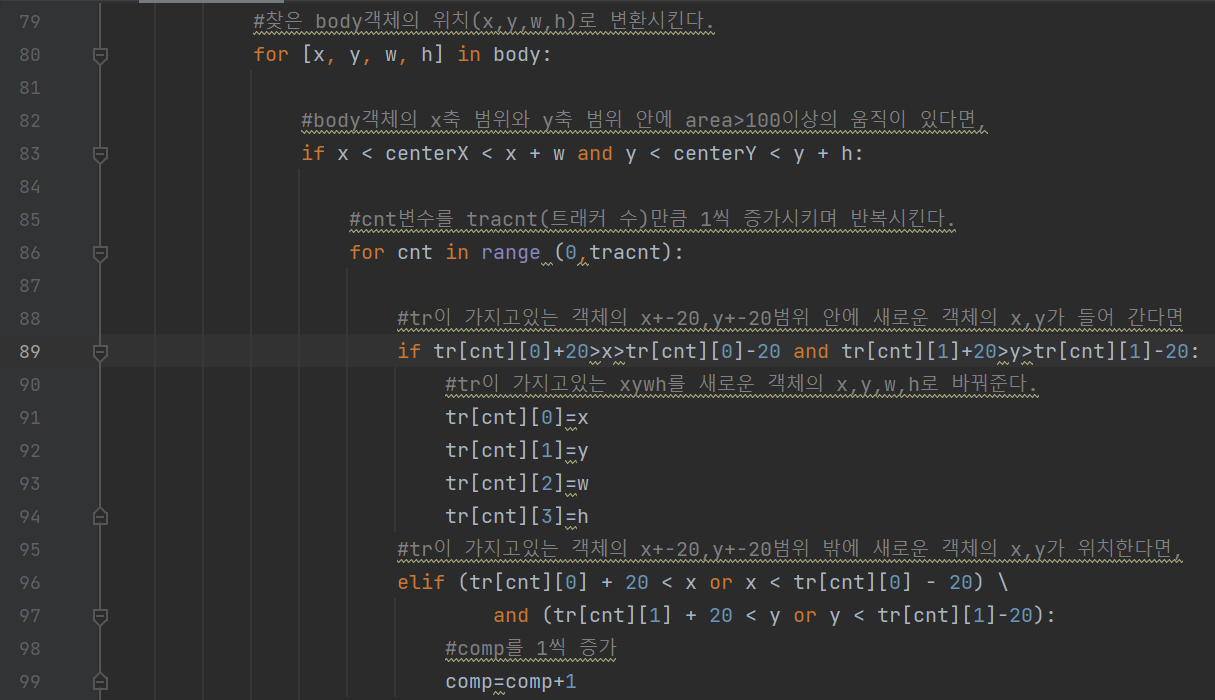 찾은 객체(body)의 x,y,w,h값을 추출한다. 그리고 x,y가 움직임이 검출되었던 좌표(centerX,centerY)를 포함하고 있다면, 이미 객체를 검출하고 트래킹하고 있는 tr리스트에 비교하며 tr에 들어있는 좌표의 오차범위(+-20)안에 있다면 새로운 객체라고 판단하지않고, tr리스트에 찾은 객체의 좌표를 넣어서 갱신시킨다. 하지만 만약 기존에 있던 객체 리스트(tr)의 오차범위에 걸리지 않는다면 comp를 1증가 시킨다.
찾은 객체(body)의 x,y,w,h값을 추출한다. 그리고 x,y가 움직임이 검출되었던 좌표(centerX,centerY)를 포함하고 있다면, 이미 객체를 검출하고 트래킹하고 있는 tr리스트에 비교하며 tr에 들어있는 좌표의 오차범위(+-20)안에 있다면 새로운 객체라고 판단하지않고, tr리스트에 찾은 객체의 좌표를 넣어서 갱신시킨다. 하지만 만약 기존에 있던 객체 리스트(tr)의 오차범위에 걸리지 않는다면 comp를 1증가 시킨다.
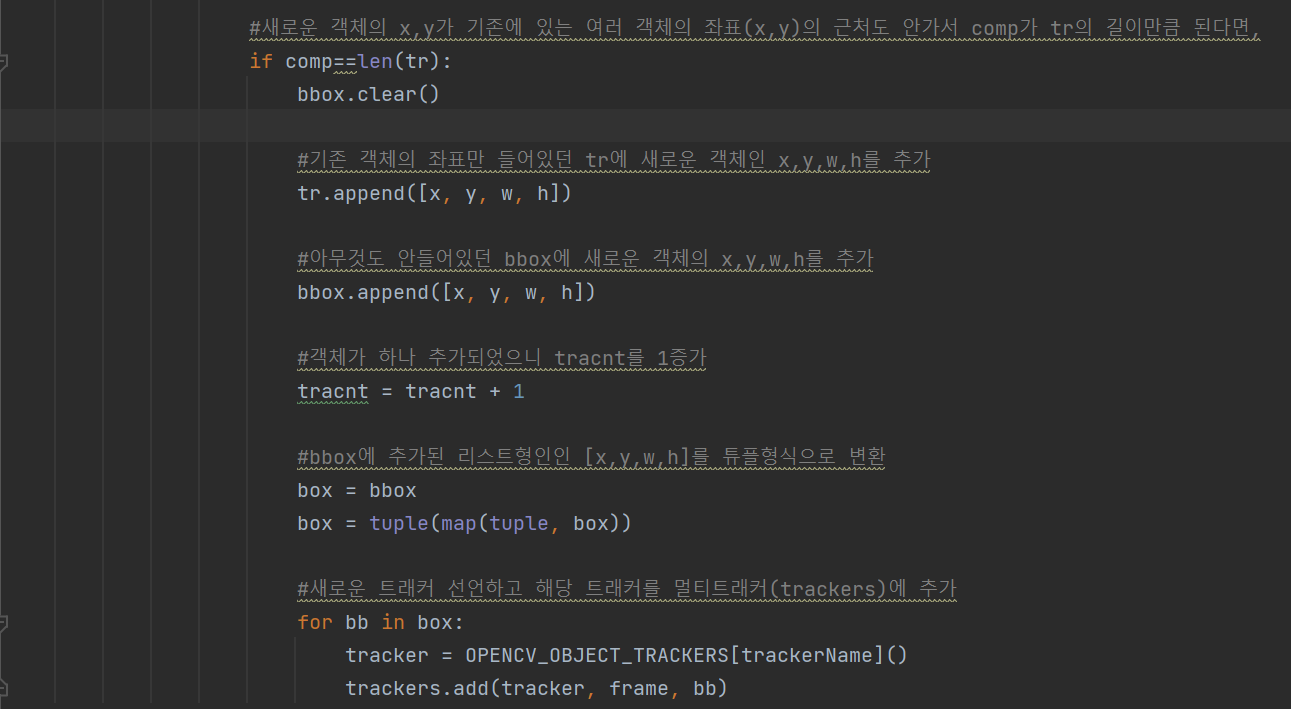 그렇게 가지고 있던 모든 객체의 좌표 리스트에 속하지 않아서 comp를 증가시켜 tr길이만큼 된다면, tr리스트에 해당 객체의 x,y,w,h를 추가시킨다. 그리고 bbox에도 추가시키며 box에 옮겨서 tuple형태로 만들어주고 트래커를 만들어주고, 만든 트래커를 멀티트래커에 추가해준다.
그렇게 가지고 있던 모든 객체의 좌표 리스트에 속하지 않아서 comp를 증가시켜 tr길이만큼 된다면, tr리스트에 해당 객체의 x,y,w,h를 추가시킨다. 그리고 bbox에도 추가시키며 box에 옮겨서 tuple형태로 만들어주고 트래커를 만들어주고, 만든 트래커를 멀티트래커에 추가해준다.
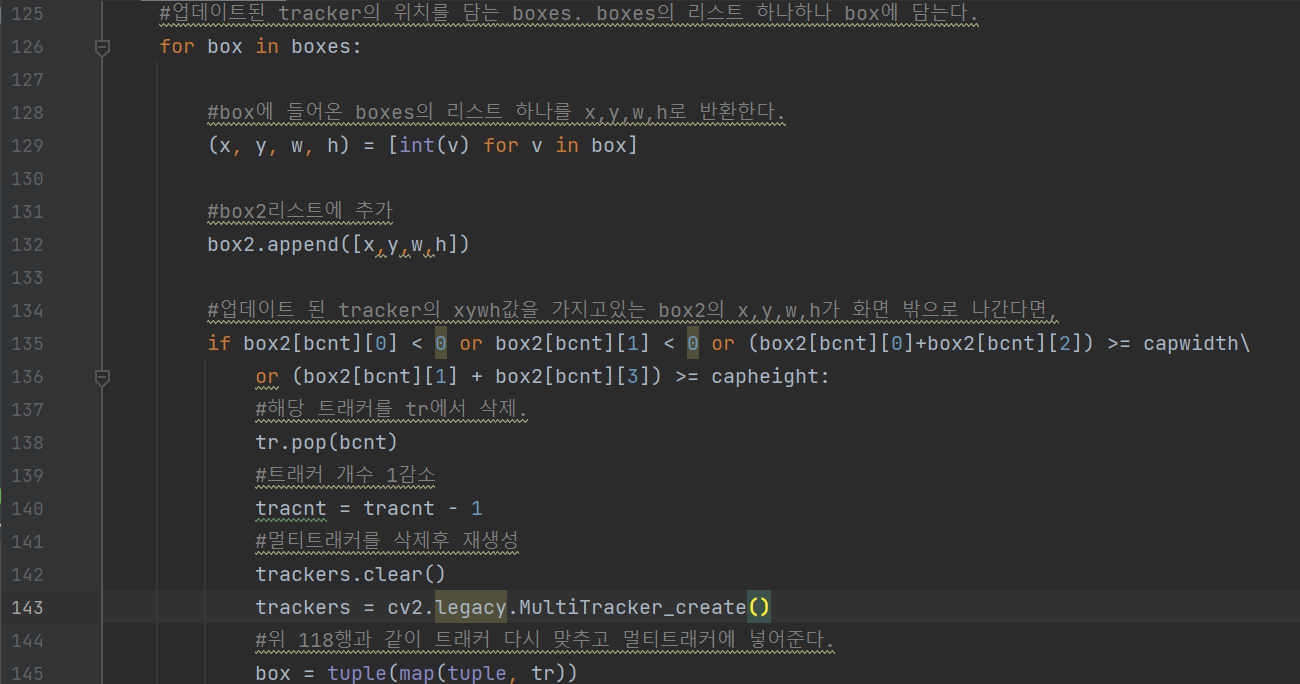
 boxes는 이미 트래커가 트래킹하고있는 좌표를 포함하는 변수로써 box로 리스트 하나하나 받아 옮긴다. 그리고 box로 옮긴 정보를 x,y,w,h로 빼내어 트래커의 x,y,w,h가 화면 밖으로 나간다면, 그 트래커의 좌표를 tr에서 빼낸다. 그리고 트래커 개수를 담고있는 tarcnt를 1감소시키고, 모든 트래커를 삭제해주고 다시 tr에 있는 트래커 좌표들을 트래킹해준다.
boxes는 이미 트래커가 트래킹하고있는 좌표를 포함하는 변수로써 box로 리스트 하나하나 받아 옮긴다. 그리고 box로 옮긴 정보를 x,y,w,h로 빼내어 트래커의 x,y,w,h가 화면 밖으로 나간다면, 그 트래커의 좌표를 tr에서 빼낸다. 그리고 트래커 개수를 담고있는 tarcnt를 1감소시키고, 모든 트래커를 삭제해주고 다시 tr에 있는 트래커 좌표들을 트래킹해준다.
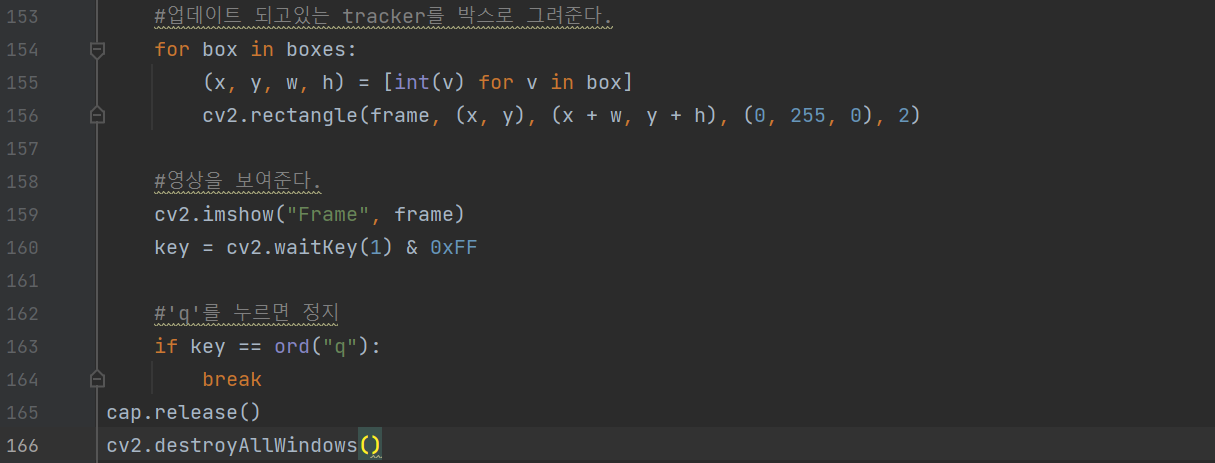 업데이트 되고있는 트래커의 좌표를 활용하여 초록색 상자를 만들어주고, 보여준다.
업데이트 되고있는 트래커의 좌표를 활용하여 초록색 상자를 만들어주고, 보여준다.
연구 결과
프로그램 실행 결과
1) 객체 인식을 통한 대략적인 인원 파악은 Tracking Count가 가능하므로 대략적인 파악은 특수적일 때 한해서만 가능할 것으로 보인다.
2) 일정 분량의 비디오를 재생시켜 지나가는 사람이 총 몇 명인지 셀 수 있지만, 코드의 최적화 성능이 좋지 못해 실시간으로 지나가는 사람을 세는 것은 가능하나, 성능저하(FPS 저하)로 인하여 상용화하기엔 보완이 필요하다. 또한, 객체가 중첩될 때, 너무 빠른 속도로 지나갈 때, 카메라와의 거리가 적절치 않을 때 인식률이 높지 않아 연구를 계속해 결과물을 보완한다면 더욱 정밀한 객체 추적이 가능할 것으로 보이며 추가로 해당 프로그램에서 사용된 full body.XML은 학습된 오픈 데이터지만 객체 인식률이 높지 못했다.
3) 우리가 full body.XML을 사용자지정 데이터로 만들어서 더욱 다양한 학습을 진행했다면 원하는 결과값의 근사치에 다다를 수 있었을 것으로 기대된다.
4) 연구 대상은 폐쇄회로 카메라와 연계된 프로그램의 객체 인식 기능이다. 폐쇄회로 카메라와 연계된 객체 인식 기능은 지역의 범죄예방 및 치안유지에 이바지함을 목표로 한다. 측정 도구로는 실제 폐쇄회로 카메라와 접목해야 하지만 임상시험에서는 휴대전화 카메라로 녹화된 비디오를 사용했다. 연구 절차는 아래와 같다. haar cascade의 밝기 변화 기능에 frame 당 변화된 픽셀값을 접목하여 CSRT tracker를 활용해 객체 추적 기술을 구현했다.
결론 및 한계점
결론
1) 이번 프로젝트에서 OpenCV에서 제공하는 객체 검출 알고리즘을 사용하여 움직이는 사람들을 인식하는 프로그램을 개발하였다. 이 프로그램을 가지고 특정 지역에 설치하여 시간대 별로 인구 이동 수에 대한 결과값을 뽑아내고자 하였다. 이러한 결과값을 가지고 지구대의 순찰 주기를 정하는데 사용할 수도 있고, 관광지의 방문객 수 데이터를 수집하는데 활용할 수 있다. 이번 프로젝트에서 사용한 객체 검출 알고리즘을 사용하여 테스트한 결과 움직이는 객체를 인식할 수 있다는 것을 확인하였고 이에 대한 결과값도 얻을 수 있었다.
2) 본 프로젝트에서 사용한 OpenCV의 객체 검출 알고리즘은 CSRT 방식으로 움직이는 객체를 인식 할 수 있다는 것을 확인했다.
한계점
1) 구현을 완료한 후 테스트를 진행하는 부분에 있어 특정 영상에서는 객체가 빠르게 움직여 생기는 잔상을 객체로 인식하는 것을 확인하였다. 이러한 결과가 발생하는 이유는 교사학습 기반의 딥러닝 방식으로 구현한 것이 아니라 OpenCV내에서 구현된 알고리즘을 사용하여 구현했기 때문에 발생한 것으로 추측한다. 또한, 저조도 환경에서 어떻게 영상을 보정하여 객체를 검출할 것인지에 대한 고민이 부족했다. 저조도 환경에서는 노이즈 및 영상의 밝기로 인해서 객체를 인식함에 있어서 오작동이 일어날 확률이 높아지기 때문에 이러한 점에 대해서 고찰이 필요할 것으로 보인다.
2) 객체 검출 방식을 앞서 언급했듯이 교사학습 방식의 딥러닝 방식으로 개선할 것이다. 대표적인 딥러닝 모델에는 Tensorflow, Pytorch등이 있다. 이러한 방식을 채택했을 경우 좀 더 정확한 객체를 인식할 수 있고, 특정 객체를 위주로 학습을 시키게 되면 학습된 객체만 검출하여 사용할 수 있다는 장점이 있다.
3) 저조도 환경의 영상은 OpenCV내에서 제공하는 영상처리 기능들이 존재하기 때문에 해당 알고리즘에 대한 공부가 이루어진 이후 개선해 나갈 것이다.
4) 구현한 프로그램의 기능들이 미완이라 정확한 테스트가 이루어지지 못한 것에 아쉬움이 있다. 하지만 어느 정도 객체를 검출하는 성과도 이뤄냈다. 앞으로 위에서 언급한 개선사항과 연구를 통해서 발전해 나갈 것이다.
댓글남기기